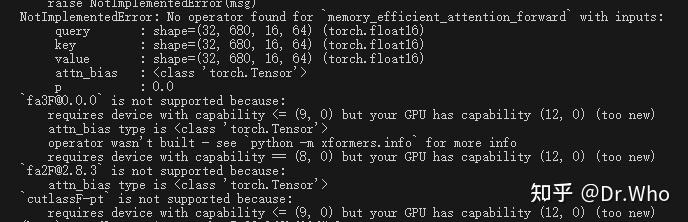
错误提示
在本地代码可以正常的使用,但是因为 xformers 官方还没有正式支持 50 系列的显卡,
所以直接使用 pip 安装再调用 memory_efficient_attention 时会报错提示显卡太新!
所以折腾了一下也是在 autodl 上租的 5090 上跑通了代码。
一个简单的解决方式.
cuda: 12.8
torch: 2.7.1
flash_attn: 2.8.0 因为直接使用 pip 安装 flash_attn 时会卡住,所以可以直接在 GitHub 的 release 上下载 whl 文件然后直接安装。
torch 和 flash_attn 其实也可以使用更高版本的只有保证 xformers, torch, flash_attn 三者版本对应就行。
xformers:
git clone https://github.com/facebookresearch/xformers.git git checkout v0.0.31 pip install -v --no-build-isolation .